
从训练到推理:创建用于图像识别的神经网络
传统的图像处理软件依赖特定任务的算法,而深度学习软件是利用网络实现的用户训练算法,来识别好的和坏的图像或区域。
幸运的是,训练神经网络的专用算法和图形用户界面(GUI)工具的出现使生产商能够以更轻松、更快速、更实惠的方式进行神经网络训练。生产商可以从深度学习GUI工具中得到什么?使用这些工具有何感受?
1、训练:创建深度学习的模型
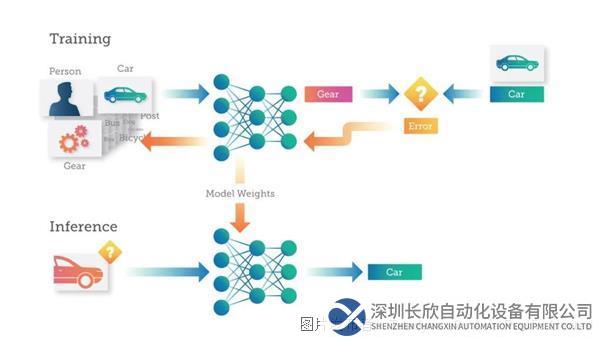
训练是通过向深度神经网络(DNN)提供可以学习的数据来“教授”深度神经网络(DNN)执行所需任务(例如图像分类或将语音转换为文本)的过程。DNN对数据代表的内容进行预测。然后将预测中的错误反馈给网络,升级人工神经元之间的连接强度。收到的数据越多,DNN学到的内容就越多,直到DNN做出的预测能达到预期的准确性水平。
例如,考虑训练一个DNN,该DNN的目的是将图像识别为三个不同类别之一——人、汽车或机械齿轮。
通常情况下,使用DNN的数据科学家将会形成一个预先组装的训练数据集,这个数据集由数千张图像组成,每张图像都标记为“人”、“汽车”或“齿轮”。这个数据集可以是一个现成的数据集,比如谷歌的Open Images,其中包括900万张图像、近6000万张图像级标签,以及其他更多内容。

谷歌Open Images中的注释方式:图像级标签、边界框、实例分割和可视化关系。
如果数据科学家的应用对于现有解决方案来说过于专业,那么可能需要构建自己的训练数据集,收集和标记最能代表DNN需要学习的图像。
训练过程中,每张图像会被传递至DNN,然后DNN会对图像所代表的内容进行预测(或推断)。每个错误都会反馈给网络,从而提高在下一次预测中的准确性。
此处的神经网络预测一张“汽车”的图像是“齿轮”。然后,这种错误通过DNN进行回传,网络内的连接会得到更新,进行错误纠正。下次将相同的图像提交至DNN时,DNN很可能会做出更正确的预测。
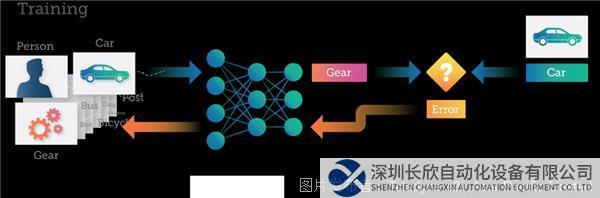
这种训练过程继续进行,图像被输入至DNN,权重得到更新,进行错误纠正,反复不断地重复这个过程数十或数千次,直到DNN能够以所需的准确度进行预测。这时,将认为DNN“经过训练”,并且生成的模型可以用于对新图像进行分类。
2、调整神经网络
神经网络的输入、隐藏层和输出的数量高度依赖于你要解决的问题和你的神经网络的特定设计。训练过程中,数据科学家试图引导DNN模型达到预期的准确度。这通常需要运行多次甚至数百次实验,尝试进行不同的DNN设计,这些设计因神经元和层数的不同而不同。
输入和输出之间是神经元和网络的连接——隐藏层。对于许多深度学习项目来说,1-5层神经元就已够用,因为只评估少数特征来进行预测。但是,任务更复杂、变量和考虑因素更多的情况下,需要更多层神经元。处理图像或语音数据可能需要数十到数百层的神经网络(每层执行特定的功能),以及与神经网络连接的数百万或数十亿个权重。
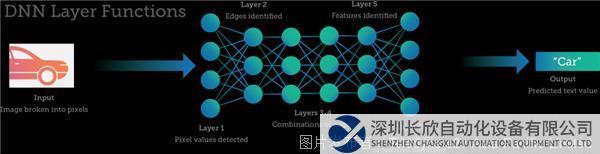
多层DNN简化示例,其中包含各层可能执行的任务类型。
3、从样本采集开始
一般需要数百甚至数千张手动分类的图像来训练系统并创建具有高度可预测性的对象分类模型。但事实证明,采集并注释如此复杂的数据集是开发过程中的一大障碍,阻碍了深度学习在主流视觉系统中的采用。
深度学习非常适用于光照、噪声、形状、颜色和纹理等变量常见的环境。一个展示深度学习优势的实际示例是对拉丝金属等纹理表面的划痕进行检测。有些划痕亮度不够,对比度接近纹理背景本身。因此,传统技术通常无法可靠定位这些类型的缺陷,尤其在不同样本的形状、亮度和对比度各不相同的条件下。图1说明了金属片材的划痕检测。通过热图图像清楚显示缺陷,突出显示缺陷位置的像素。
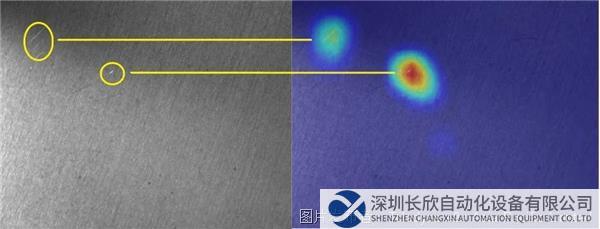
表面检查显示的是左侧有划痕的拉丝金属板,分类算法输出的热图显示的是右侧缺陷。其中分类算法在用输入样本训练神经网络时自动生成。需要注意的是,我们添加了黄色圆圈来显示原始图像和热图之间的对应关系。
从头开始训练的深度神经网络通常需要采集数百甚至数千张图像样本。然而,当今的深度学习软件通常经过预训练,因此用户可能只需要采集数十个额外的样本就可以使系统适应特定的应用。
与此相反,使用常规分类构建的检查应用需要采集“优质”和“劣质”图像进行训练。但使用异常检测等新型分类算法时,用户可以只训练优质样本,只需要少量劣质样本进行最终测试。
虽然图像样本采集并无捷径可走,但过程已经越来越简单化。如需采集图像,技术人员可使用Sapera LT,这是一款免费的图像采集和控制软件开发工具包(SDK),可以用于Teledyne DALSA的2D/3D相机和图像采集卡。训练神经网络使用的GUI工具Astrocyte可以与Sapera LT接口连接,从相机中采集图像。例如,用户在手动模式下采集PCB组件上的图像时,会用手移动PCB,改变相机的位置、角度和距离,从而生成PCB组件的一系列视图。
4、利用视觉工具训练神经网络
用户获得图像后就应进行神经网络训练。只需单击“训练”(Train)按钮即可在Astrocyte中进行训练,使用默认超参数开始训练过程。用户可以修改超参数,以便最终模型实现更高的准确性。
如需验证准确性,用户可以使用一组不同的图像来测试模型,并选择使用诊断工具,例如分类模型的混淆矩阵。混淆矩阵是一个NxN表格(其中N=类别个数),显示每个类别的成功率。在这个示例中(见图2),颜色编码用于表示模型的精度/召回率,绿色表示精度/召回率超过90%。
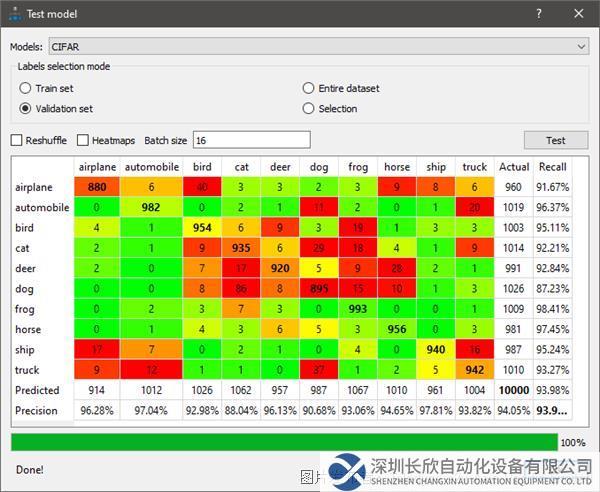
在混淆矩阵中,双击结果字段会打开Astrocyte图像选项卡中的相关图像,以便进行进一步研究。
另一个非常重要的诊断工具是热图。例如,进行异常检测时,热图会突出显示缺陷的位置。看到热图后,用户会根据适当原因评估图像质量的优劣。如果图像质量很好但却被归类为劣质图像,用户可以查看热图获取更多详细信息。神经网络将遵循用户提供的输入内容。
一个很好的示例是在螺丝检查应用中使用热图:

Astrocyte通过相应热图显示右上方圈出的缺陷。左上角显示的是完美的图像。
热图还可以揭示模型侧重的图像细节或特征,这些细节或特征与图像目标场景或对象的期望分析无关。根据Astrocyte模块,可以使用不同类型的热图生成算法。
5、运行GUI工具
解释深度学习GUI工具方法的最佳方式是进行展示。异常检测模型训练是训练神经网络的基础,因此这里提供了一个简短的教程,其中包含使用Astrocyte逐步进行异常检测的方法。
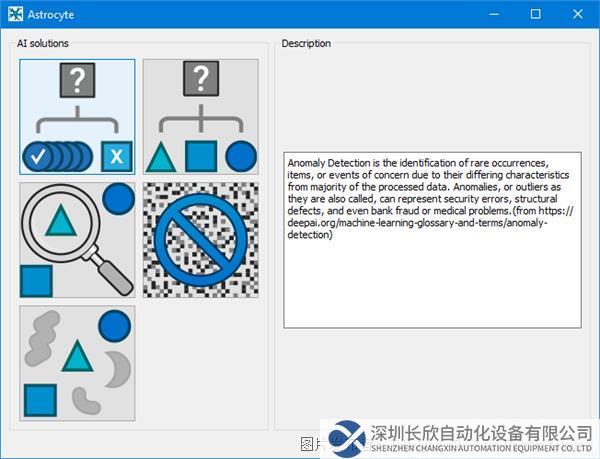
第1步:启动Astrocyte应用程序,在启动界面选择“异常检测”(Anomaly Detection)模块:
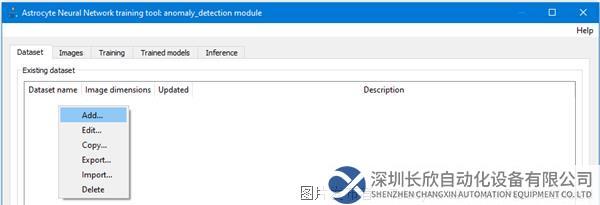
第2步:在“数据集”(Dataset)选项卡中,右键单击并选择“添加数据集”(Add Dataset)。
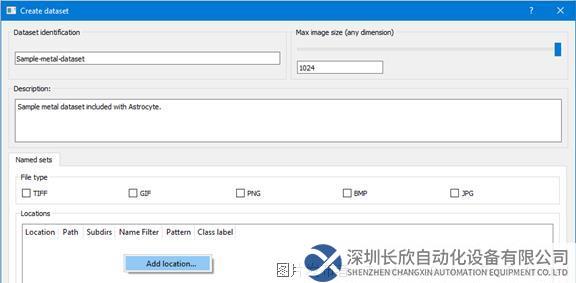
第3步:输入数据集名称和描述,在“数据库”(Databases)面板中右键单击选择“添加数据库”(Add Database)。
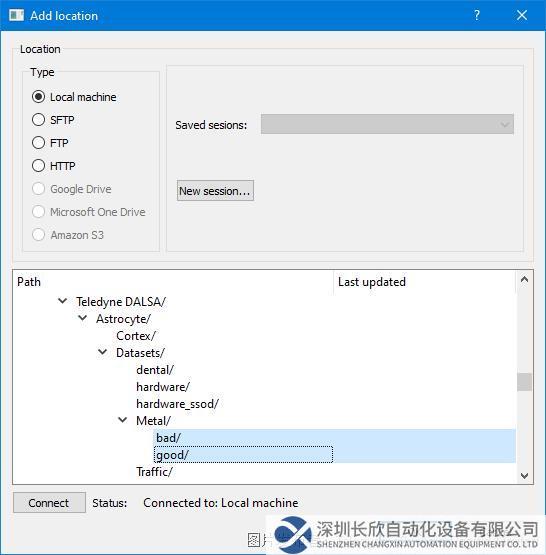
第4步:在“添加“(Add)位置对话框中,导航到包含训练图像数据集的文件夹。同时选择正常(好)和异常(坏)目录,然后单击OK。
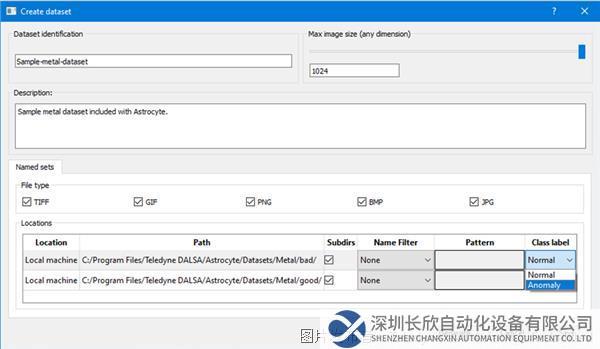
第5步:每个目录均使用下拉列表分配类标签:“正常”(Normal)或“异常”(Anomaly)。然后单击“生成”(Generate)将数据集添加至内部Astrocyte服务器。
生成过程完成后,如果数据集中的图像大小不同,则会显示图像大小分布分析仪对话框;否则,如果图像大小相同,会自动调整到指定的最大图像大小,对话框不会显示。如有必要,使用“图像校正”(Image Correction)对话框来校正图像。
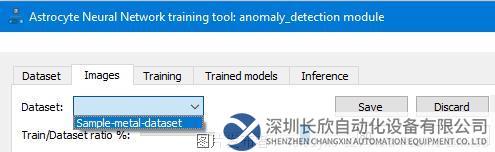
第6步:在“图像”(Image)选项卡中,使用“数据集”(Dataset)下拉列表选择所需的数据集。然后验证数据集图像和标签,并进行必要更改。如果修改数据集,单击“保存”(Save)更新并保存Astrocyte服务器上的数据集。
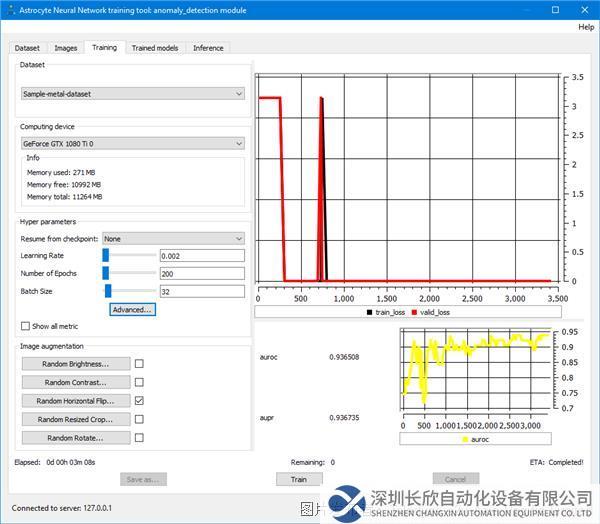
第7步:在“训练”(Training)选项卡中,选择数据集并单击“训练”;在每批完成时更新训练损失和度量图,并显示训练统计数据。
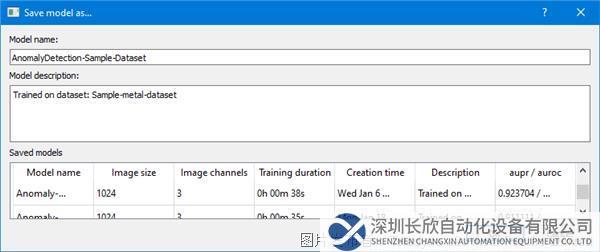
第8步:训练完成时,会显示一个保存模型的提示,单击“是”(Yes)。输入模型名称和描述,然后单击OK。现在您可以使用模型进行测试。Astrocyte也使用同样直观的GUI引导用户完成这个过程。
6、优化推理我们需要完善受训者吗?
一旦以可接受的准确度水平完成训练,我们就会得到一个加权神经网络——本质上是一个庞大的数据库。这个数据库使用效果良好,但在速度和功耗方面可能不会达到最佳效果。有些应用无法容忍高水平的延迟:例如智能交通系统甚至自动驾驶汽车。自主无人机或其他电池供电系统可能需要在较小功率范围内运行以满足飞行时间需求。
DNN越大、越复杂,训练和运行所消耗的计算、内存和能量就越多。因此可能不适用于您的给定应用或设备。在这种情况下,需要在训练后简化DNN,从而降低功耗和延迟,即使这种简化会导致预测准确性略微降低。
在深度学习中,这种优化是一个相对较新的领域。芯片和AI加速器供应商通常会创建
SDK来帮助用户执行此类任务——使用专门针对特定架构调整的软件。涉及的芯片范围很广,包括GPU、CPU、FPGA和神经处理器。每种芯片都有自己的优势。例如,英伟达的TensorRT突出了公司在GPU核心方面的专业性。相比之下,Xilink的Vitis AI支持公司的SoC,例如Versal,包括CPU、FPGA和神经处理器。
供应商通常会提供两种变通方法:修剪和量化。修剪是指删除对最终结果贡献较小的神经网络部分的操作。这一操作可以减小/降低网络的大小/复杂性,但不会显著影响输出精度。第二种方法是量化——减少每个权重的位数(例如,用FP16或量化INT8/4/2替换FP32)。执行复杂难度较低的计算,可以提高速度和/或减少所需的硬件资源。
7、投入生产:转向推理
一旦我们的DNN模型完成训练和优化,就可以投入使用:针对以前看不见的数据进行预测。和训练过程一样,图像作为输入,DNN尝试对其进行分类。Astrocyte。
Teledyne DALSA提供Sapera Processing和Sherlock两个软件包,其中包括一套图像处理工具和一个用于运行人工智能模型的推理引擎。
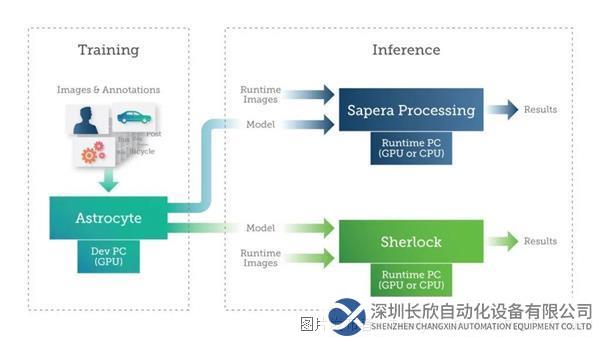
Teledyne DALSA AI训练和推理用软件包
用户可以在使用GPU或CPU的PC或嵌入式设备上实现推理。根据应用的尺寸、重量和功耗(SWAP)需求,用户可以利用各种技术在嵌入式设备(如GPU、FPGA和专用神经处理器)上实现深度学习推理。
8、深度学习:日益简化?
从本质上讲,神经网络是复杂难懂但功能强大的工具。几乎有无限机会来调整和优化每一个神经网络,以最佳方式解决您的特定问题。广泛的优化范围以及新研究和工具的快速发展可能会让人不知所措,即使经验丰富的从业者也不例外。
但这并不意味着您无法将这些工具的优势融入到您未来的视觉系统中。向GUI工具的演变正在使视觉系统中的深度学习民主化。借助将用户从AI学习和编程的严格要求中解放出来的软件,制造商可以使用深度学习来更好地分析图像,效果超过任何传统的算法。不久的将来,与我们传统的检查员相比,这种类型的GUI工具表现可能会更出色。






同类文章排行
- 万马高分子助力,国内首条公里级大长度环保
- 主营产品有哪些?
- 购买后产品发什么快递?
- 节能转型,电机产业链有哪些变革性机会?
- 更紧凑而高效的机器人世界
- 机器手臂的创新应用:轻薄短小、智能高效
- 产品供货周期需要多久?
- 当半导体碰上 AMR,来一场智能化的精彩
- 坚持科技是第一生产力
- 通向智能工厂的硬核技术,哪些和你有关?
最新资讯文章
- 英孚康是罗克韦尔的替代品?不止如此
- 欧洲航天局利用MVG设备大幅增强新型 H
- Profinet转canopen网关连接
- DATALOGIC得利捷 | 物流之眼利
- 施耐德电气与标领智能装备强强联合,共创电
- 【有现货】KB-LS10N-C KB-L
- 华北工控打造网安专用主板,基于飞腾D20
- PLC通讯革新:EtherNetIP转P
- 华北工控ATX-6152:高度集成化!提
- 巴斯夫成功完成Ethernet-APL试
- HRPG-1000N3 系列:1000W
- RQB60W12 系列:60W 1/4
- NPB-450-NFC 系列:450W
- VFD 系列:150W~750W 工业用
- NGE12/18 系列:12W/18W
- 工业现场ModbusTCP转EtherN
- DJM / FT系列:12V/38~15
- SI06W8/DI06W8 系列:超宽压
- NGE100 (U) 系列:100W 环
- LOP-200/300系列:200W &